Rabu, 03 Juli 2013
Basis Data Terdistribusi (Distributed Database)
Bagian I: Pengantar Basis Data Terdistribusi
Pengantar: Dalam posting hari ini akan dibahas gambaran umum mengenai basis data terdistribusi (distributed database), khususnya untuk menjawab pertanyaan mendasar “Apa itu basis data terdistribusi?”
Basis data terdistribusi (distributed database) adalah suatu basis data yang berada di bawah kendali sistem manajemen basis data (DBMS) terpusat dengan peranti penyimpanan (storage devices)
yang terpisah-pisah satu dari yang lainnya. Tempat penyimpanan ini
dapat berada di satu lokasi yang secara fisik berdekatan (misal: dalam
satu bangunan) atau terpisah oleh jarak yang jauh dan terhubung melalui
jaringan internet. Penggunaan basis data terdistribusi dapat dilakukan
di server internet, intranet atau ekstranet kantor, atau di jaringan
perusahaan.
Untuk
menjaga agar basis data yang terdistribusi tetap up-to-date, ada dua
proses untuk menjaganya, yakni replikasi dan duplikasi. Dalam replikasi,
digunakan suatu perangkat lunak untuk mencari — atau lebih tepatnya
melacak — perubahan yang terjadi di satu basis data. Setelah perubahan
dalam satu basis data teridentifikasi dan diketahui, baru kemudian
dilakukan perubahan agar semua basis data sama satu dengan yang lainnya.
Proses replikasi memakan waktu yang lama dan membebani komputer karena
kompleksitas prosesnya. Sementara itu, proses duplikasi tidak sama dan
tidak sekompleks replikasi. Dalam proses ini, satu basis data dijadikan
master, kemudian diperbanyak menjadi sejumlah duplikat. Selama proses
duplikasi berlangsung, perubahan hanya boleh dilakukan pada basis data
master agar data lokal tidak tertimpa.
Pengguna (user) dari sebuah basis data terdistribusi dapat mengakses basis data melalui dua jenis aplikasi, yakni
- aplikasi lokal: aplikasi yang tidak memerlukan data dari tempat lain
- aplikasi global: aplikasi dengan kebutuhan akan data dari tempat lain
Dalam
proses perancangan basis data terdistribusi, harus diperhatikan aspek
transparansi, yaitu interaksi user terhadap basis data merupakan
interaksi dengan satu sistem secara utuh. Transparansi harus terlihat
dalam dua hal, yaitu
- Distribusi: para pengguna harus dapat berinteraksi dengan sistem secara keseluruhan sebagai satu sistem yang utuh. Kesatuan ini harus ada pada kinerja sistem dan metode pengaksesan.
- Perubahan (transaksi): Setiap transaksi (penambahan, penghapusan, atau peng-update-an) harus mempertahankan integritas antara basis data yang berbeda-beda dalam satu sistem. Setiap transaksi harus dibagi ke dalam sejumlah subtransaksi, yang tiap-tiap darinya memberikan pengaruh pada keseluruhan sistem basis data.

ilustrasi basis data terdistribusi
Bagian II: Pemanfaatan Basis Data Terdistribusi dan Masalah Transparansi
Pengantar: Setelah mendapat gambaran mengenai basis data terdistribusi pada posting
dua pekan yang lalu, pertanyaan yang mungkin timbul selanjutnya adalah
“Untuk apa basis data terdistribusi diimplementasikan?” Posting kali ini
akan diawali dengan bahasan mengenai hubungan antara basis data
terdistribusi dengan distributed computing. Pembahasan dilanjutkan
dengan kelebihan dan kekurangan basis data terdistribusi, juga masalah
(issue) transparansi dalam pengelolaan basis data terdistribusi.
Dengan demikian, pemanfaatan basis data terdistribusi dapat memudahkan perolehan informasi dari berbagai lokasi yang berbeda, bahkan berjauhan, di samping meningkatkan kinerja sistem dengan beberapa komputer yang bekerja bersamaan.
Basis data terdistribusi pada dasarnya adalah bagian dari sistem komputer terdistribusi, atau disebut juga distributed computing. Distributed computing
sendiri adalah sistem yang dapat membuat komputer-komputer yang berbeda
dan bekerja secara bersamaan dapat saling bertukar informasi dalam satu
kesatuan sistem. Dengan basis data terdistribusi, operasi basis data
dapat dikendalikan dari satu mesin (komputer) dan dijalankan pada
mesin-mesin yang lain.
Sistem
komputer terdistribusi, tentunya juga dengan basis data terdistribusi,
dapat membantu penyelesaian berbagai masalah, khususnya yang berkaitan
dengan bisnis. Sistem komputer terdistribusi dapat mempercepat aplikasi
dengan membagi operasi-operasi pada mesin yang berbeda. Selain itu,
komputer-komputer yang berpartisipasi dalam sistem komputer
terdistribusi boleh jadi saling berjauhan letaknya. Dengan demikian,
pemanfaatan basis data terdistribusi dapat memudahkan perolehan
informasi dari berbagai lokasi yang berbeda, bahkan berjauhan, di
samping meningkatkan kinerja sistem dengan beberapa komputer yang
bekerja bersamaan.
Kelebihan dan Kekurangan Basis Data Terdistribusi
Pemanfaatan
basis data terdistribusi dapat memberikan manfaat bagi sistem yang
mengimplementasikannya. Hal ini disebabkan oleh kelebihan-kelebihan yang
dimilikinya, antara lain
- kinerja yang lebih baik karena data ditempatkan di tempat yang sesuai dengan kebutuhan dan komputer-komputer dalam sistem dapat bekerja secara paralel, sehingga pembebanan pada komputer (server) menjadi seimbang.
- alasan ekonomis, yaitu bahwa merancang sistem yang terdiri atas jaringan komputer-komputer kecil (sederhana) dibandingkan dengan mengimplementasikan komputer tunggal yang canggih.
- alasan modularitas, yaitu bahwa sistem-sistem yang bekerja dalam basis data terdistribusi dapat dimodifikasi, ditambah, atau dikurangi tanpa memengaruhi modul lain (sistem lain dalam basis data terdistribusi). Dengan pembagian lokasi data, jika terjadi masalah atau musibah pada sistem, tidak semua data terancam, melainkan hanya data pada tempat-tempat tertentu.
- alasan organisasi dan otonomi pada sistem-sistem yang berpartisipasi, misalnya pada suatu kantor perusahaan, terdapat beberapa departemen. Dengan basis data terdistribusi, data-data perusahaan dapat disebar ke tiap-tiap departemen yang bertanggung jawab atasnya.
Akan tetapi, di samping kelebihan-kelebihan yang dimilikinya, basis data terdistribusi juga memiliki kendala, antara lain
- masalah kompleksitas, yaitu bukan pekerjaan yang mudah untuk membuat basis data yang tersebar terlihat sebagai satu kesatuan. Administrator basis data mempunyai tugas ekstra untuk menjaga agar basis data yang tersebar di berbagai lokasi terlihat transparan. Di samping itu, pemeliharaan sistem-sistem yang berlainan lebih kompleks ketimbang pemeliharaan sistem besar yang utuh sebagai satu kesatuan. Tingginya kompleksitas juga dapat menyebabkan pembengkakan biaya.
- masalah desain, yaitu bahwa desain yang dibuat harus memperhatikan arsitektur komputer yang terdiri atas sistem-sistem yang terpisah, selain itu juga memperhatikan data yang difragmentasi (dipecah-pecah) ke dalam lokasi berlainan. Perubahan dari basis data terpusat menjadi terdistribusi juga menjadi masalah karena belum ada standar metodologi dalam konversi DBMS terpusat menjadi DBMS terdistribusi.
- keamanan data, yaitu bukan hanya satu sistem yang harus diberi proteksi keamanan data, melainkan juga fragmen-fragmennya yang tersebar di berbagai lokasi, juga jalur komunikasi antarsistem.
- kendala mempertahankan integritas karena dalam menjaga integritas sistem melalui jaringan juga dapat memakan resource yang besar dari jaringan.
Masalah-Masalah yang Harus Diperhatikan (Issues) dalam Basis Data Terdistribusi
Dalam
aplikasi sistem manajemen basis data terdistribusi (DDBMS), ada beberapa
masalah (issue), yang harus diperhatikan, antara lain:
- transparansi
- perancangan (desain)
- pemrosesan query
- manajemen transaksi
- arsitektur dan middleware
Issue Transparansi dalam Basis Data Terdistribusi
Dalam
posting dua pekan yang lalu, telah dibahas bahwa distribusi dan
transaksi data dalam basis data terdistribusi harus transparan. Secara
lebih rinci, untuk memelihara transparansi dalam basis data
terdistribusi, ketiga aspek transparansi berikut ini harus diperhatikan:
- Jaringan: keberadaan jaringan dalam implementasi basis data harus seolah-olah tidak ada dalam pandangan pengguna. Penggunaan bahasa query (query language) harus tidak terikat pada lokasi penyimpanan data. Selain itu, lokasi penyimpanan data tidak boleh disertakan pada penamaan data. Sebagai akibatnya, semua nama yang digunakan pada basis data harus unik di seluruh sistem. Selain itu, pencarian data dalam basis data terdistribusi harus dibuat efisien dan pemindahan lokasi data pada basis data harus dibuat mudah.
- Replikasi: data pada basis data terdistribusi mungkin memiliki replika pada lokasi yang berbeda. Pembuatan replika ini harus ada di bawah kendali sistem, bukan pengguna. Termasuk di dalam aspek ini modifikasi data, yaitu tiap-tiap replika harus selalu diperbaharui dan mekanisme kontrol konkurensi harus menangani replika berdasarkan konsistensi pembacaan.
- Fragmentasi: jika basis data terdistribusi bersifat terfragmentasi (secara detailnya akan dibahas pada posting selanjutnya), setiap query yang dimasukkan oleh pengguna harus ditangani sistem sedemikian sehingga mempengaruhi relasi-relasi yang terbagi dalam fragmen-fragmen. Sistem juga harus bisa menangani query sedemikian sehingga keseluruhan sistem dapat memperoleh hasil dari satu query dari lokasi yang berbeda-beda.
Bagian III: Perancangan Basis Data Terdistribusi
Pengantar: Dalam posting bagian ini akan dibahas perancangan basis data
terdistribusi berikut masalah-masalah yang berkaitan dengannya.
terdistribusi berikut masalah-masalah yang berkaitan dengannya.
Seperti
halnya proses perancangan sistem lainnya, perancangan basis data
terdistribusi juga memerlukan serangkaian proses analisis dan desain.
Termasuk di dalam proses ini adalah analisis kebutuhan beserta
proses-proses perancangan, yakni desain secara konseptual bersama dengan
desain tampilan (view) informasi; desain distribusi yang melibatkan pengaturan pembagian data; kemudian desain fisik (lihat gambar).

bagan proses perancangan basis data terdistribusi
Fragmentasi
Dalam
basis data terdistribusi, fragmentasi dilakukan pada relasi-relasi yang
ada pada basis data. Fragmentasi membagi suatu relasi yang ada menjadi
sejumlah fragmen atau pecahan relasi yang tetap mempertahankan keutuhan
informasi semula. Kelebihan dari fragmentasi, yang menjadi alasan
dilakukannya adalah dimungkinkannya pemrosesan data secara paralel dan
penempatan tupel relasi, yang berisi sejumlah informasi, pada tempat
yang tepat, yaitu yang paling membutuhkannya. Fragmentasi sendiri
terbagi atas empat jenis, yaitu:
- primary horizontal: sebuah relasi R(A1, …, An) difragmentasi berdasarkan himpunan predikat-predikat relasi PR = {p1, …, pn}. Tiap-tiap predikat merupakan perbandingan yang digunakan dalam aljabar relasional, yang dapat melibatkan operator perbandingan =, ?, <, atau >.
- derived horizontal: pembuatan partisi suatu relasi R berdasarkan partisi yang dibuat pada relasi lain, misalkan S. Satu atau beberapa atribut di R mengacu kepada primary key pada S.
- vertical: fragmentasi ini dilakukan dengan memisah-misahkan atribut-atribut dari skema relasi R ke dalam skema-skema Ri. Setiap fragmen relasi harus memiliki primary key relasi asli.
- hybrid: fragmentasi yang mempunyai pola campuran dari ketiga relasi di atas
Ilustrasi Fragmentasi
Misalkan ada dua relasi sebagai berikut:
PEGAWAI(NoPeg, NamaPeg, Posisi, Gaji, NoDep) DEPT(NoDep, NamaDep, Lokasi)
Contoh fragmentasi untuk tiga jenis fragmentasi yang telah disebutkan di atas adalah sebagai berikut:
- dalam fragmentasi primary horizontal, dimisalkan ada
himpunan predikat yang diakses oleh aplikasi yang berbeda. Satu aplikasi
memperoleh informasi pegawai dengan posisi DBAdmin, sementara aplikasi
lainnya memperoleh informasi pegawai dengan gaji lebih besar dari Rp 15
juta. Predikat sederhana dapat dinyatakan dalam himpunan sbb: .
Selanjutnya, predikat-predikat dapat dinyatakan ke dalam himpunan dari
minterm, yaitu
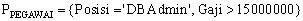 . Selanjutnya, predikat-predikat dapat dinyatakan ke dalam himpunan dari minterm, yaitu sebagai berikut
. Selanjutnya, predikat-predikat dapat dinyatakan ke dalam himpunan dari minterm, yaitu sebagai berikut
- m1 = Posisi = ‘DBAdmin’ ^ Gaji > 15000000
- m2 = Posisi ? ‘DBAdmin’ ^ Gaji > 15000000
- m3 = Posisi = ‘DBAdmin’ ^ Gaji = 15000000
- m4 = Posisi ? ‘DBAdmin’ ^ Gaji = 15000000
- dalam fragmentasi derived horizontal, misalkan DEPT dipartisi berdasarkan predikat Lokasi = ‘Bandung’, sehingga ada dua partisi
DEPT1 = sLokasi = ‘Bandung’(DEPT) DEPT2 = sLokasi ? ‘Bandung’(DEPT)
sementara, itu PEGAWAI dipartisi berdasarkan partisi DEPT sebagai berikut:
PEGAWAIi PEGAWAI left outer join DEPTi
- dalam fragmentasi vertical, relasi PEGAWAI(NoPeg, NamaPeg, Posisi, Gaji, NoDep) difragmentasi ke dalam fragmen relasi PEGAWAI1(NoPeg, NamaPeg, Gaji) dan PEGAWAI2(NoPeg, Posisi, NoDep).
Ketepatan Fragmentasi
Fragmentasi dikatakan tepat apabila memenuhi syarat-syarat berikut:
- kelengkapan: dekomposisi relasi R ke dalam fragmen-fragmen R1, …, Rn dikatakan lengkap jika setiap tupel R dapat ditemukan dalam fragmen Ri mana pun.
- rekonstruksi: jika relasi R terdekomposisi ke dalam fragmen-fragmen R1, …, Rn, terdapat operator relasional
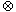 sedemikian sehingga
sedemikian sehingga 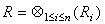 .
. - disjoint: jika sebuah relasi R dipartisi, sebuah tupel dalam R, jika ditemukan dalam fragmen Ri, tidak akan ditemukan dalam fragmen Rj dengan i ? j.
Alokasi
Dalam
basis data terdistribusi, alokasi mengacu kepada distribusi data ke
tempat yang optimal. Ada tiga aspek dalam memastikan alokasi menjadi
optimal, antara lain
- biaya minimal, yang mencakup aspek komunikasi, penyimpanan, dan pemrosesan (pembacaan dan update); biaya mengacu pada waktu dan biaya jaringan
- kinerja, yang mencakup waktu respons dan throughput
- konstrain pemrosesan dan penyimpanan per situs (tempat menyimpan data)
Alokasi – Kebutuhan Informasi
Untuk
dapat mengalokasikan basis data terdistribusi secara optimal, dibutuhkan
informasi-informasi tentang sistem sebagai berikut:
- informasi basis data
- skema konseptual basis data dan jumlah situs tersedia
- jumlah, ukuran, dan selektivitas fragmen per relasi global
- informasi aplikasi
- jumlah query aplikasi
- rata-rata jumlah akses baca dariquery ke dalam sebuah fragmen
- rata-rata jumlah akses update dari query ke dalam sebuah fragmen
- matriks yang menunjukkan query mana yang meng-update dan/atau membaca fragmen tertentu
- situs asal tiap-tiap query dijalankan
- informasi situs
- unit cost penyimpanan data dalam satu situs
- unit cost pemrosesan data dalam satu situs
- informasi jaringan
- komunikasi antara dua situs, mencakup antara lain bandwidth dan tunda (latency)
Replikasi
Sistem
basis data terdistribusi dapat menyimpan duplikat dari data yang sama
dalam site yang berbeda agar perolehan informasi yang semakin cepat dan
toleransi kesalahan. Proses ini disebut replikasi. Replikasi pada relasi
bersifat redundan pada dua atau lebih situs.
Replikasi
pada relasi disebut replikasi penuh bila relasi tersebut disimpan pada
semua situs. Basis data disebut redundan penuh jika tiap-tiap site
mengandung duplikat dari keseluruhan basis data.
Replikasi dilakukan karena memiliki kelebihan sebagai berikut:
- jika situs asli yang menyimpan relasi R mengalami kegagalan, relasi R tetap dapat diakses melalui replikanya
- query pada relasi R dapat berjalan secara paralel di simpul (situs) yang berbeda
- lebih sedikit transfer data, yaitu tidak perlu lagi mengambil data suatu relasi melalui jaringan karena sudah ada replika dalam situs lokal.
Namun, proses replikasi juga memiliki kelemahan, antara lain
- proses update yang lebih rumit karena setiap replika relasi R harus di-update.
- kendali atas konkurensi yang lebih rumit karena update terhadap replika secara konkuren dapat menyebabkan basis data menjadi tidak konsisten sehingga diperlukan mekanisme khusus dalam penanganan konkurensi.
Sementara itu, dalam melakukan replikasi, ada dua strategi, yaitu
- sinkron: sebelum seluruh proses transaksi update dinyatakan selesai, data yang telah dimodifikasi disinkronkan ke setiap duplikatnya; proses ini harus menunggu hingga data di tempat penyimpanan duplikat selesai ditulis sebelum dilakukan perubahan lainnya sehingga menjadi lebih kompleks
- asinkron: copy data diperbaharui secara periodik berdasarkan data utama yang diperbaharui; proses penulisan data selesai tanpa perlu menunggu penulisan data di tempat penyimpanan duplikat selesai; proses ini memang meningkatkan kinerja sistem namun risikonya, inkonsistensi data bisa terjadi.
Bagian IV: Pemrosesan Query Terdistribusi
Pengantar: Dalam posting bagian ini akan dibahas masalah (issue) lainnya dalam basis data terdistribusi, yaitu pemrosesan query terdistirbusi, berikut pertimbangan dan contoh kasus dalam pembuatan query.
Pemrosesan query pada basis data terdistribusi berbeda dari pemrosesan query pada basis data terpusat. Query-query pada relasi global perlu disesuaikan agar dapat menganani relasi-relasi dalam fragmen. Pembuatan query pada perancangan basis data terdistribusi dapat diilustrasikan dengan bagan di bawah ini.

Bagan pembuatan query terdistribusi
Pada basis data terpusat, evaluasi query harus memperhatikan faktor pengaksesan storage (disk), yakni jumlah blok pada hard disk yang dibaca/tulis. Sementara itu, dalam pemrosesan query pada basis data terdistribusi, diperlukan pula pertimbangan dari sisi
- transmisi data melalui jaringan
- peningkatan kinerja yang potensial akibat pemrosesan query secara paralel
Dalam membuat query pada basis data terdistribusi, perlu diperhatikan hal-hal sebagai berikut:
- penyesuaian dari query relasi global ke query terhadap fragmen, yaitu bahwa ekspresi relasi global dalam query harus disesuaikan menjadi ekspresi relasi fragmen; relasi global harus dapat direkonstruksi (dibuat terlihat global) dari fragmen-fragmennya
- penyederhanaan ekspresi aljabar relasional, juga deteksi dan penghilangan redundant
- pemilihan strategi join yang optimal (khususnya pada program yang melakukan “semi-join“)
- pemilihan rencana pemrosesan query yang optimal
Sebagai contoh, jika dimisalkan terdapat relasi global PARTS(PartNo, OrderNo, Price) yang dipartisi menjadi
- PARTS1:= σ0≤PartNo≤300(PARTS)
- PARTS2:= σ301≤PartNo≤500(PARTS)
- PARTS3:= σ501≤PartNo≤999(PARTS)
Query Q = σ25≤PartNo≤350(PARTS) pada relasi global dapat diubah menjadi bentuk query fragmen berikut:
- mengganti relasi global menjadi definisi fragmen-fragmennya:
Q1 = σ25≤PartNo≤350(PARTS1 ∪ PARTS2 ∪ PARTS3) - melakukan pushdown pada tiap-tiap fragmen:
Q2 = σ25≤PartNo≤350(PARTS1) ∪ σ25≤PartNo≤350(PARTS2) ∪ σ25≤PartNo≤350(PARTS3)
Pemrosesan Paralel pada Query Fragmen
- Jika dimisalkan sebuah relasi R difragmentasi secara horizontal (seperti contoh sebelumnya) menjadi R1 ∪ … ∪ Rn, aljabar relasional seleksi dan proyeksi menjadi
σF(R) ≡ (σF(R1)) ∪ … ∪ (σF(Rn))
πattr(R) ≡ (πattr(R1)) ∪ … ∪ (πattr(Rn)) - Fungsi-fungsi agregat (query Q(R) diasumsikan menghasilkan relasi satu kolom)
- min(Q(R)) ≡ min(Q(R1), …, Q(Rn))
- max(Q(R)) ≡ max(Q(R1), …, Q(Rn))
- sum(Q(R)) ≡ sum(Q(R1)) + … + sum(Q(Rn))
- Operasi R join S
Jika dimisalkan relasi S difragmentasi berdasarkan fragmentasi relasi R, sedemikian sehingga R = R1 ∪ R2 dan S = S1 ∪ S2, setiap fragmen dari R hanya perlu digabungkan (di-join) dengan fragmen dari S yang bersesuaian dengannya.
Pemrosesan Join Query
Jika terdapat relasi-relasi pada tempat (situs) yang terpisah, misalnya relasi R di situs A1, S di A2, dan T di A3, query R join S join T yang dilakukan pada situs Ai, harus ditampilkan hasilnya pada situs Ai. Strategi pemrosesan query yang mungkin adalah sebagai berikut:
- Meng-copy salinan semua relasi R, S, dan T ke situs Ai, kemudian melakukan join secara lokal di Ai
- Melakukan join secara bertahap, sbb:
- menyalin R ke A2 dan menghasilkan temp1 = R join S
- temp1 disalin ke A3 dan menghasilkan temp2 = temp1 join T
- temp2 sebagai hasil akhir dipindahkan ke Ai
Strategi join di atas dapat dipilih dengan mempertimbangkan faktor-faktor berikut:
- jumlah data yang ditransfer (salin)
- biaya (resource) yang diperlukan untuk transfer data antarsitus
- kecepatan pemrosesan di tiap situs
Operasi join dapat pula dioptimalkan dengan menggunakan strategi semijoin. R semijoin S ≡ πattr(R) (R join S). Jika dimisalkan relasi R disimpan di A1 dan S di A2, kemudian dilakukan operasi R join S pada A1), strategi semijoin dapat diilustrasikan sebagai berikut:
- lakukan proyeksi di A1 hanya dengan atribut yang dimiliki R dan S; temp1 := πattr(R) ∩ attr(s)(R)
- hasil temp1 disalin ke A2 dan di-join dengan S; temp2 := S join temp1; perhatikan bahwa temp2 adalah juga S semijoin R
- temp2 disalin ke A1 dan dilakukan operasi R join temp2
Strategi semijoin di atas dapat meningkatkan efisiensi operasi join karena data yang dipertukarkan melalui jaringan menjadi lebih kecil. Untuk membuat join lebih efisien, dapat diimplementasikan program (semi-)join yang memiliki pemroses query (query processor) untuk membuat partisi dari sederetan join seperti R1 join R2 join … Rn menjadi kumpulan semijoin yang lebih efisien. Pemilihan semijoin dilakukan dengan mempertimbangkan perpindahan data (resource dan waktu) beserta konstrain yang terkait, misalnya waktu respon maksimum dari query.
Bagian V: Multidatabase dan Arsitektur Client/Server (Penutup: Contoh Sistem dengan Oracle)
Pengantar: Posting terakhir ini akan membahas aspek multidatabase,
termasuk proses pembuatannya dengan proses integrasi basis data, juga
aplikasi pendukung basis data terdistribusi, yaitu arsitektur
klien/server. Sebagai penutup akan dibahas pula contoh sistem basis data
terdistribusi menggunakan Oracle.
Multidatabase
Suatu sistem basis data terdistribusi adakalanya dibentuk dari beberapa basis data yang berlainan. Sistem seperti ini disebut multidatabase,
yang pembentukannya dilakukan dengan integrasi basis data. Dalam
melakukan integrasi ini, boleh jadi ada ketidakseragaman antara basis
data-basis data yang membentuknya dan mengakibatkan konflik, baik konflik skema (akibat ketidakseragaman skema relasi) maupun konflik data (akibat ketidakakuratan isi, misalnya presisi, besaran dan satuan, juga data yang tidak tepat atau sudah tidak berlaku [obsolete]). Oleh karena itu, perlu diperhatikan metode penyelesaian konflik yang terjadi.
Penyelesaian
konflik saat integrasi basis data harus memerlukan analisis yang
mendalam akan komponen basis data dan tidak dapat diotomatisasi. Adapun sebelum dilakukan integrasi, komponen basis data harus dipersiapkan terlebih dahulu, khususnya untuk penanganan konflik. Proses ini disebut restrukturisasi. Ilustrasi restrukturisasi dan integrasi basis data dapat dilihat pada bagan berikut:

Bagan Proses Restrukturisasi dan Integrasi Basis Data
Penyelesaian konflik pada restrukturisasi (untuk integrasi) basis data dapat dilakukan dengan menggunakan view,
yaitu relasi/tabel bentukan virtual yang bukan bagian dari skema relasi
itu sendiri, tetapi dapat diperlakukan sebagaimana relasi melalui query dan view lain. View hanya perlu disimpan definisinya di kamus data tanpa perlu relasinya.
Berikut ini adalah konflik yang dapat terjadi pada proses integrasi basis data berikut contoh penanganannya:
- konflik antartabel
- antara dua tabel
- nama tabel (homonim/sinonim), dapat diselesaikan dengan definisi view sendiri
- struktur tabel, seperti jumlah atribut berbeda di dua tabel yang informasinya sama, dapat diselesaikan dengan membuang atribut yang keberadaannya tidak di semua relasi atau menambahkan atribut yang kurang pada relasi yang kekurangan atribut (bila perlu dengan nilai default-nya)
- integrity constraint, misalnya pada dua situs terdapat tabel yang sama tetapi isi atribut primary key-nya berbeda, dapat diselesaikan dengan memberikan primary key tambahan yang berisi informasi situs relasi itu disimpan
- antara banyak tabel, misalnya pada dua komponen basis data jumlah relasinya tidak sama tetapi informasinya sama, dapat diselesaikan dengan penggabungan relasi dengan view
- antara dua tabel
- konflik antaratribut
- antara dua atribut
- nama atribut (homonim/sinonim), dapat diselesaikan dengan penggantian nama (rename) atribut di view
- integrity constraint, misal tipe data, dapat diselesaikan dengan fungsi-fungsi konversi, seperti to_char(int) atau to_int(char), pada view
- antara banyak atribut, misalnya dalam penyimpanan informasi nama orang dalam tabel yang satu digunakan dua atribut (kolom): nama depan dan nama belakang, sementara pada tabel yang lain digunakan satu atribut nama lengkap; konflik ini dapat diselesaikan dengan penggabungan string atau pemisahan string dengan fungsi substring
- antara dua atribut
- konflik tabel-atribut, dapat merupakan kombinasi dari permasalahan di atas
Arsitektur Klien/Server
Basis
data terdistribusi adalah bagian dari sistem komputer terdistribusi.
Arsitektur klien/server adalah model arsitektur perangkat lunak yang
umum digunakan dalam sistem ini. Sistem dipisahkan antara klien dan
server; kerjanya adalah sebagai berikut: sistem klien melakukan
permintaan dan sistem server memproses permintaan tersebut.
Fungsionalitas dalam arsitektur klien/server dapat dibagi menjadi tiga,
yaitu:
- fungsi presentasi, mencakup antarmuka seperti peranti input dan form
- fungsi aplikasi, spesifik terhadap aplikasi yang digunakan
- fungsi manajemen data, yang mengelola akses data dalam arsip atau basis data
Bagan ilustrasi arsitektur klien/server adalah sebagai berikut:

Fungsionalitas basis data pada arsitektur klien/server dibagi menjadi dua:
- front-end, berhubungan dengan pengguna dan mencakup penanganan masukan, antarmuka pengguna, dan pembuatan report.
- back-end, berhubungan dengan akses data dan penanganan query, kontrol concurrency, dan recovery
Untuk menghubungkan keduanya, digunakan SQL atau application program interface, dapat berupa ODBC atau JDBC.
Ada dua jenis sistem server yang umum digunakan, yaitu server transaksi dan server data. Perbedaannya adalah
- pada server transaksi, klien hanya perlu mengirimkan permintaan melalui application program interface, seperti ODBC dan JDBC; selanjutnya serangkaian prosedur (transaksi) yang berhubungan dengan pemrosesan query dijalankan di server
- pada server data, seluruh fungsionalitas back-end dilakukan di klien, termasuk pemrosesan query data; server mengirimkan seluruh data yang diminta ke klien, bukan hasil query
Contoh Sistem: Sistem Basis Data Terdistribusi dengan Oracle
Basis
data terdistribusi dapat diimplementasikan dengan berbasiskan sistem
Oracle. Dalam implementasinya, sistem basis data terdistribusi dengan
Oracle dapat digolongkan menjadi dua:
- sistem basis data terdistribusi homogen: seluruh
sistem menggunakan basis data Oracle yang bertempat di satu atau
beberapa mesin; Oracle yang digunakan boleh jadi berbeda versi, tetapi
aplikasi harus dapat memahami perbedaan fungsionalitas yang ada di
setiap simpul (basis data) sistem

Ilustrasi Sistem Basis Data Terdistribusi Homogen - sistem basis data terdistribusi heterogen:
sedikitnya satu sistem bagian tidak menggunakan basis data Oracle; agar
dapat saling berkomunikasi, perbedaan ini dapat dijembatani dengan
menerapkan salah satu dari berikut:
- Oracle Transparent Gateway yang menggunakan layanan heterogen pada server Oracle (Oracle Heterogenous Services) dan agen yang spesifik terhadap sistem pada sistem non-Oracle
- konektivitas generik (generic connectivity), yang dapat diimplementasikan di server Oracle dan berupa Heterogenous Services ODBC agent atau Heterogenous OLE DB
agent; dengan mengimplementasikannya, tidak diperlukan lagi aplikasi
agen yang spesifik-sistem, tetapi sumber data harus kompatibel dengan
ODBC atau OLE DB agar dapat diakses

Ilustrasi Sistem Basis Data Terdistribusi Heterogen

Langganan:
Posting Komentar (Atom)